

什么是Spark?Spark部署模式介绍
Apache Spark 是一种快速、通用、可扩展的大数据分析引擎。于2009年诞生于加州大学伯克利分校AMPLab,2012年开源,2013年6月成为了Apache孵化项目,2014年成为了Apache顶级项目。项目使用Scala语言进行编写,并提供了包括Scala、Python、Java在内的多种语言的编程接口。
2012年,开源
2013年,Apache孵化项目
2014年,Apache顶级项目
2014年5月,Spark 1.0.0 版本发布
2016年1月,Spark 1.6.0 版本发布
2016年7月,Spark 2.0.0 版本发布
2020年6月,Spark 3.0.0 版本发布
总结:
Apache Spark就是一个计算引擎,可以对大数据平台上的数据进行计算处理。
Spark与MapReduce的对比
在大数据的生态圈中有很多的计算引擎,我们学习过的Hadoop,其中就包括了一个分布式计算引擎MapReduce。那么MapReduce和Spark有什么区别?
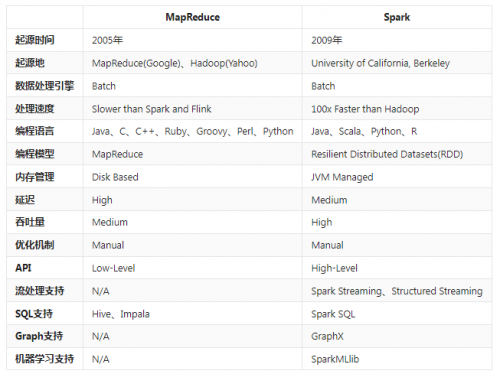
框架对比
运行流程对比
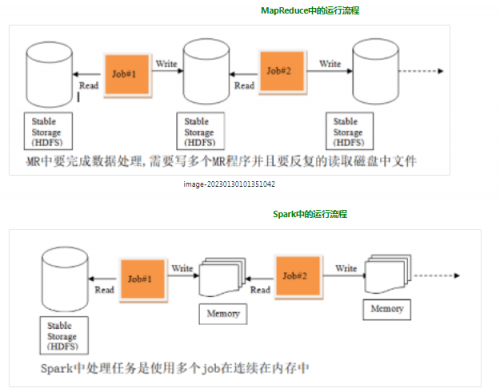
MapReduce在计算过程中,MapTask会将计算结果落地到磁盘,由ReduceTask去拉取数据继续计算。最终的计算结果也会落地在磁盘上。如果涉及到比较复杂的计算,需要多个Job串联的时候,每一个Job都得从磁盘拉取数据开始。在这个过程中会产生大量的磁盘IO,非常消耗时间。
Spark在计算过程中,会将计算过程中产生的数据保存在内存中,不会落地磁盘。后续的计算任务直接从内存中拉取数据,计算速度非常快。但是Spark比起MapReduce来说,会占用更高的内存。
Spark的组件

Spark的特点
Simple
简单。Spark支持Java、Python和Scala的API,还支持超过80种高级算法,是用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便的在这些Shell中使用Spark集群来验证解决问题的方法。
Fast
快速。与Hadoop的MapReduce相比,Spark基于内存的计算要快100倍以上,基于磁盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
Scalable
可伸缩性。在遇到计算资源不足的时候,可以简简单单的通过扩展集群规模来实现计算能力的扩展。
Unified
统一性。Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming、Structured Streaming)、机器学习(Spark MLlib)、图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
Spark部署模式介绍
在部署Spark的时候,可以分为不同的模式,大体来说可以有如下几种模式:
Local模式:
即本地模式,在这种模式下,没有分布式的思想,所有的工作都在一个节点上完成。在这个机器上开启一个独立的进程工作,其中会开启指定数量的线程,来模拟分布式的思想,完成计算的任务。通常情况下只是用来做本地的测试工作、验证工作。
Standalone模式:
Standalone是Spark内置的资源调度框架,在这种模式下,Spark中的各个角色以独立的进程存在,如Master、Worker等。支持完全分布式模式。
YARN模式:
YARN是大数据生态圈中的一个资源调度框架,Spark也是可以基于YARN进行资源调度,完成计算任务的。在这种模式下,Spark中的各个角色都运行在YARN的Container内。
Spark常见的部署模式为Standalone模式与YARN模式,因为这两种模式下可以支持完全分布式集群,可以充分利用集群中所有机器的性能完成计算任务。同时也可以基于Spark的可伸缩性,当计算资源不足的时候,只需要简简单单的扩展节点,即可拓展计算能力。当然,除了Standalone和YARN模式之外,还有其他的资源调度框架,例如:Mesos、Kubernetes等,而Spark也是支持这样的资源调度框架的。




相关推荐HOT
更多>>
如何添加Java环境变量?
要添加Java环境变量,可以按照以下步骤:并安装Java开发工具包(JDK)、找到Java安装路径、设置JAVA_HOME环境变量、添加Java可执行文件路径到PATH...详情>>
2023-05-04 11:00:56
从零开始学Java之String字符串的编码
对很多小白来说,可能不明白什么是字符编码,也不知道为什么要有字符编码,所以先来给大家简要地介绍一下字符编码。详情>>
2023-05-04 10:21:02
新手速来!几步带你掌握MyBatis Plus
Mybatis-Plus(简称MP)是一款Mybatis的增强工具,它是在Mybatis的基础上实现的简化开发工具。Mybatis-Plus给我们提供了开箱即用的CRUD操作、自动...详情>>
2023-04-28 10:57:09
学习java需要什么基础?基础知识有哪些?
网络编程:了解基本的网络编程概念和协议,熟悉 Java 网络编程 API。建议在学习 Java 之前,先学习一些基础的编程语言,如 C 或 Python 等,这...详情>>
2023-04-28 10:41:14热门推荐



技术干货










 京公网安备 11010802030320号
京公网安备 11010802030320号